CouchDBの思想
複数 DB 間での同期機能が優れている CouchDB を個人開発で利用したいと思っているので、入門するために調べた内容をまとめる。 主に公式 Document の内容を自分なりにまとめたもの。
Why CouchDB?
A Different Way to Model Your Data
https://docs.couchdb.org/en/stable/intro/why.html
CouchDB は Web アーキテクチャとリソース、メソッド、表現の概念を大きく取り入れており、それによってデータのクエリ、マッピング、結合、filter 処理を強力な方法で強化する。
Syntax and Semantics
https://docs.couchdb.org/en/stable/intro/why.html#syntax-and-semantics
例えば、名刺は会社や人それぞれで記載される詳細な内容は異なるかもしれないが、ほとんどは共通する内容が書いてある。 会社名、部署名、電話番号、Email などが一般的に共通する内容であるが、人によっては Fax の番号が書いてあったりもする。 これを Relational Database で表現しようとすると、Fax カラムを追加して、Fax を名刺に記載しない人の場合は None であることをデータとして保存しなければならない。 実際にはそんなことをしなくても、Fax 番号データが存在していないだけで Fax を持っていないことが暗示される。 CouchDB は大まかに同じ種類の文書であれば多様性があっても同じデータとして扱うことができ、現実世界の文書を扱うようにデータを集約することができる。
CouchDB Replication
https://docs.couchdb.org/en/stable/intro/why.html#couchdb-replication
2 つ以上の CouchDB を同期することができる。冗長化するために複数のマシン間のデータベースを同期させ、ニューヨークと東京で物理的に離れた場所間でもデータのやり取りができる。2 つ以上の CouchDB を同期することができる。冗長化するために複数のマシン間のデータベースを同期させ、ニューヨークと東京で物理的に離れた場所間でも Replication ができる。
結果整合性
https://docs.couchdb.org/en/stable/intro/consistency.html
CouchDB は RDBMS のように可用性よりも絶対的な一貫性に重きを置くのとは対照的に、最終的な一貫性を受け入れる部分が異なる。 つまり、多くの人が同時にアクセスしているときにデータが異なって動作するということである。 一貫性、可用性、分割耐性のどの側面を優先するかという点でそれぞれのアプローチは異なる。
CAP 定理
https://docs.couchdb.org/en/stable/intro/consistency.html#the-cap-theorem
CAP 定理についておさらい
https://ja.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
ノード間のデータ複製において、同時に次の 3 つの保証を提供することはできない。 この定理によると、分散システムはこの 3 つの保証のうち、同時に 2 つの保証を満たすことはできるが、同時に全てを満たすことはできない。単一障害点があれば、ネットワーク分断が発生した際にシステムがバラバラに分裂しても、そこを基準に一貫した応答ができる(分断耐性+一貫性)が、可用性が成立しなくなる。
- 一貫性(Consistency)
- すべてのデータ読み込みにおいて、最新の書き込みデータもしくはエラーのどちらかを受け取る。
- 可用性(Availability)
- ノード障害により生存ノードの機能性は損なわれない。つまり、ダウンしていないノードが常に応答を返す。単一障害点が存在しないことが必要。
- 分断耐性(Partition-tolerance)
- システムは任意の通信障害などによるメッセージ損失に対し、継続して動作を行う。通信可能なサーバーが複数のグループに分断されるケース(ネットワーク分断)を指し、1 つのハブに全てのサーバーがつながっている場合は、これは発生しない。ただし、そのようなネットワーク設計は単一障害点をもつことになり、可用性が成立しない。RDB ではそもそもデータベースを分割しないので、このような障害とは無縁である。
CAP 定理では同時に 2 つまで保証を満たすことができるが、これを 2 つ満たす DB をそれぞれ選ぶと以下の図になる。
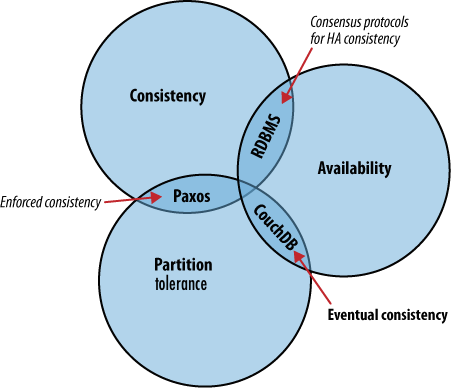
システムが大きくなり、単一の DB ノードでは負荷に耐えられない場合、懸命な解決策はサーバーを追加すること。 ノードを新たに追加する場合には、ノード間でどのようにデータを分割するか考えなければならない。 全く同じデータを共有する DB がいくつかあるのか?異なるデータセットを異なる DB サーバーに置くのか?特定の DB サーバーにのみデータを書き込み、読み込みは他のサーバーに任せるか?など
どのようなアプローチを取るにしても、常に突き当たる問題はこれらすべての DB サーバーを同期させること。あるノードにデータを書き込んだとして、別の DB サーバーへの read がその最新情報を反映していることをどうやって確認するのか? これらのイベントは数ミリ秒の間隔があるかもしれない。DB サーバーの数が少なくてもこの問題はとても複雑である。
すべてのクライアントが DB の一貫したビューを見ることが絶対的に重要な場合、あるノードのユーザーは DB への読み取りや書き込みができるようになる前に他のノードが合意するのを待つ必要がある。 この例では可用性は一貫性よりも後回しにされるが、可用性が一貫性よりも優先される場合もある。
システム内の各ノードは純粋にローカルの状況に基づいて意思決定ができる必要がある。高負荷で障害が発生し、合意に達するまで何かをする必要がある場合、迷ってしまう。 スケーラビリティを重視するのであれば合意を強制的に実行させるようなアルゴリズムは最終的にボトルネックになる。
可用性を優先するのであれば他のノードが合意に至るのを待たずにクライアントにデータベースのあるノードにデータを書き込ませることができる。 もし DB がノード間でこれらの操作を調整する方法を知っていれば、高可用性と引き換えに、ある種の最終的な一貫性を実現することができ、多くのアプリケーションで適用可能なトレードオフになる。
CouchDB では、一貫性を保証するような RDB とは異なり、一貫性を犠牲にする代わりにハイパフォーマンスなアプリケーションを簡単に構築することができる。
Local Consistency
https://docs.couchdb.org/en/stable/intro/consistency.html#local-consistency
CouchDB がクラスタで動作する方法を理解する前に、単一の CouchDB ノードの内部の仕組みを理解することが重要である。 CouchDB API は DB コアの便利で薄いラッパーを提供するように設計されている。
The Key to Your Data
https://docs.couchdb.org/en/stable/intro/consistency.html#the-key-to-your-data
CouchDB は強力な B-Tree ストレージエンジンを持っており、すべての内部データ、ドキュメント、ビューに対して B-Tree エンジンを使用している。
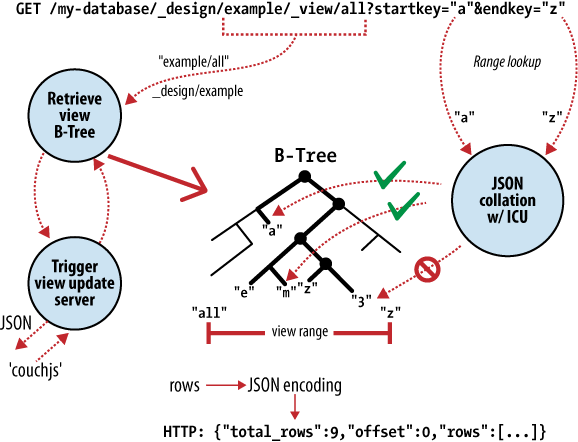
CouchDB はビューの結果を計算するために MapReduce を使用している。
MapReduce とは
https://ja.wikipedia.org/wiki/MapReduce
MapReduce は巨大なデータセットを持つ高度に並列可能な問題に対して、多数のコンピュータ(ノード)の集合であるクラスター(各ノードが同じハードウェア構成を持つ場合)もしくはグリッド(各ノードが違うハードウェア構成を持つ場合)を用いて並列処理させるためのフレームワークである。処理は、ファイルシステム(非構造的)もしくはデータベース(構造的)に格納されたデータに対して行うことができる。
Map ステップ - マスターノードは、入力データを受け取り、それをより細かい単位に分割し、複数のワーカーノードに配置する。受け取ったワーカーノードが、更に細かい単位に分割し、他の複数のワーカーノードに配置するという、より深い階層構造の分割を行うこともある。そして、各ワーカーノードは、その細かい単位のデータを処理し、処理結果を、マスターノードへと返す。
Reduce ステップ - 続いて、マスターノードが、Map ステップでの処理結果を集約し、目的としていた問題に対する答え(結果)を何らかの方法によって出力する。
MapReduce の特徴は、Map と Reduce の各ステップで並列処理が可能なことである。それぞれの Map 処理は、他の Map 処理と完全独立であり、理論的に全て並列実行することができる(実際には、データソースや CPU の数により制限がかかる)。続く Reduce ステップでは、Map ステップでの処理結果がキーごとにまとめられて Reduce 処理に送られることになるが、これも同様に並列処理が可能である。
MapReduce による一連の処理は、逐次実行アルゴリズムと比較してしばしば非効率にみえるが、MapReduce は一般の汎用サーバが取り扱うことが可能なデータ量をはるかに超える大きなデータセットに対しても適用することができる。多数のサーバを持っていれば、MapReduce を使いペタバイト級のデータの並べ替えをわずか数時間で行うことも可能である。
また、処理が並列的であることで、複数あるサーバやストレージの一部に障害が起こり、Map 処理や Reduce 処理が実行できないノードが発生した場合でも、入力データがまだ利用可能である場合は、処理を再スケジュールして実行させることが可能となる。これにより、障害に対して、しばしば処理継続中のリカバリーが可能になる。
CouchDB はドキュメントにアクセスし、key または key の range ごとに結果を表示する。これは CouchDB の B-Tree ストレージエンジンで実行される基本操作への直接マッピングである。 ドキュメントの insert と update に加えて、この直接マッピングが CouchDB の API を DB コアのラッパーであると説明する理由である。
key だけで結果にアクセスできることは、大幅な性能向上を実現することができる故にとても重要な制限事項である。 速度の大幅向上だけでなく、データを複数のノードに分割しても、各ノードに個別にクエリを実行する能力に影響を与えることはない。 BigTable、Hadoop、SimpleDB、memcached は、まさにこのような理由から、キーによるオブジェクトの検索を制限している。
No Locking
https://docs.couchdb.org/en/stable/intro/consistency.html#no-locking
RDB には同一のテーブルや行にアクセスが来た場合に処理の順序をきちんと決めてデータに不整合が起きないようにロックをかける仕組みがある。 高負荷時には RDB は実際の作業よりも、誰がどの順番で何をすればいいのかの確認に多くの時間を費やす。
CouchDB では、ロック機構の代わりに同時アクセスへの対応として MVCC(Multi-Version Concurrency Control)を使用する。 これによって高負荷の場合でも常にフルスピードで実行可能になる。

CouchDB のドキュメントは Git のようにバージョン管理されている。ドキュメント内の値を変更したいときは、そのドキュメント全体の新しいバージョンを作成し、古いものの上にそれを保存する。 そうすると同じ文書に新旧 2 つのバージョンが存在することになる。
ロックと比較するために、あるドキュメントにアクセスするための一連のリクエストを考える。
最初のリクエストはドキュメントを読み取る。これが処理されている間に 2 つ目のリクエストがドキュメントを更新する。 2 つ目のリクエストはドキュメントの完全に新しいバージョンが含まれているため、CouchDB は終了する読み取り要求を待つことなく、DB に insert が可能になる。
Incremental Replication
https://docs.couchdb.org/en/stable/intro/consistency.html#incremental-replication
Incremental Replication はドキュメントの変更が定期的にサーバー間でコピーされるプロセス。 各ノードが独立・自立しており、システム全体で競合する点が 1 つもない、いわゆる shared nothing cluster な DB を構築することが可能になる。
CouchDB のノード間の Incremental Replication を使用するといつでも好きなように任意の 2 つの DB 間でデータを同期することができる。 Replication の後、各 DB は独立して動作することができる。
この機能を使えば、クラスタ内や DB 間で cron などの job scheduler を使って DB を同期させたり、ノート PC とデータを同期させて移動中にオフラインで作業したりすることができる。 各 DB は通常の方法で使用することができ、DB 間の変更は後で双方向に同期させることができる。
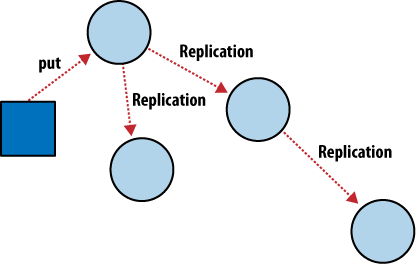
2 つの異なる DB で同じドキュメントを更新し、お互いに同期させたい場合は自動で競合を検知と conflict 解消機能がついている。 CouchDB は両方の DB で変更があることを検出するとドキュメントにフラグを立てる。
これは思ったよりも面倒ではない。Replication 中に 2 つのバージョンのドキュメントが衝突した場合、勝った方のバージョンが履歴の最終バージョンとして保存される。 代わりに CouchDB は失われたバージョンもアクセスできるようにドキュメントの履歴に残す。 conflict の解消をどのように処理するかはアプリケーションに委ねられる。選択したドキュメントのバージョンをそのままにしたり、古いものに戻したり、2 つを統合して結果を保存したりできる。